6.3 Selección de variables explicativas
Cuando se dispone de un conjunto grande de posibles variables explicativas suele ser especialmente importante determinar cuales de estas deberían ser incluidas en el modelo de regresión. Si alguna de las variables no contiene información relevante sobre la respuesta no se debería incluir (se simplificaría la interpretación del modelo, aumentaría la precisión de la estimación y se evitarían problemas como la colinealidad). Se trataría entonces de conseguir un buen ajuste con el menor número de predictores posible.
6.3.1 Búsqueda exhaustiva
Para obtener el modelo “óptimo” lo ideal sería evaluar todas las posibles combinaciones de los predictores.
La función regsubsets() del paquete leaps permite seleccionar los mejores modelos fijando el número máximo de variables explicativas.
Por defecto, evalúa todos los modelos posibles con un determinado número de parámetros (variando desde 1 hasta por defecto un máximo de nvmax = 8) y selecciona el mejor (nbest = 1).
library(leaps)
regsel <- regsubsets(fidelida ~ . , data = train)
# summary(regsel)
# names(summary(regsel))Al representar el resultado se obtiene un gráfico con los mejores modelos ordenados
según el criterio determinado por el argumento scale = c("bic", "Cp", "adjr2", "r2") (para detalles sobre estas medidas ver por ejemplo la Sección 6.1.3 de James et al., 2021).
Se representa una matriz en la que las filas se corresponden con los modelo y las columnas con predictores, indicando los incluidos en cada modelo mediante un sombreado.
Por ejemplo, en la Figura 6.7 se muestra el resultado obtenido empleando el coeficiente de determinación ajustado.
plot(regsel, scale = "adjr2")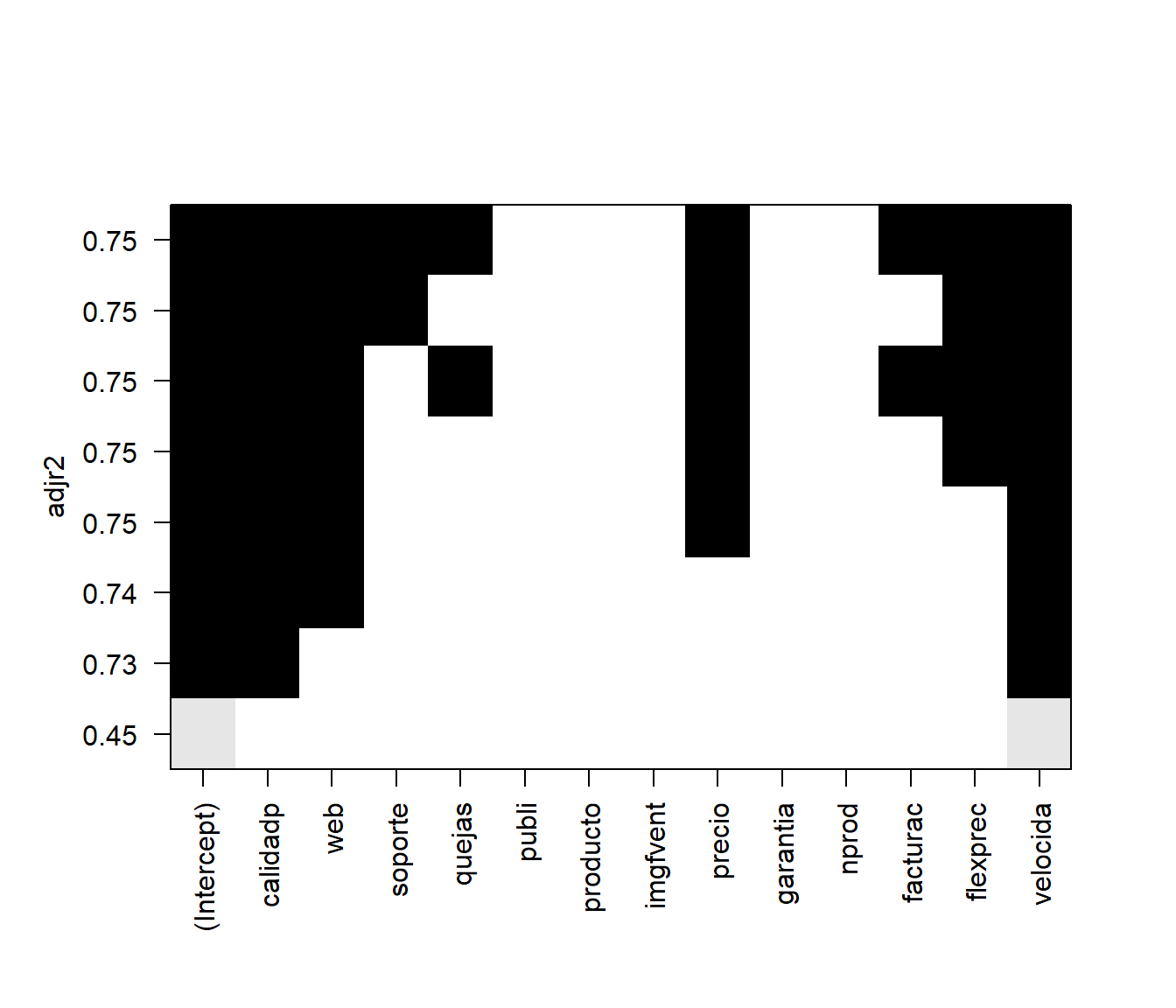
Figura 6.7: Modelos obtenidos mediante búsqueda exhaustiva ordenados según su coeficiente de determinación ajustado.
En este caso, considerando que es preferible un modelo más simple que una mejora del 2% en la proporción de variabilidad explicada, podríamos seleccionar como modelo final el modelo con dos predictores. Podemos obtener fácilmente los coeficientes de este modelo:
coef(regsel, 2)## (Intercept) calidadp velocida
## 3.332511 3.204201 7.700260pero normalmente nos interesará ajustarlo de nuevo:
modelo <- lm(fidelida ~ velocida + calidadp, data = train)Notas:
Si se emplea alguno de los criterios habituales, el mejor modelo con un determinado número de variables no depende del criterio empleado. Aunque estos criterios pueden diferir al comparar modelos con distinto número de variables explicativas.
Si el número de variables explicativas es grande, en lugar de emplear una búsqueda exhaustiva se puede emplear un criterio por pasos, mediante el argumento
method = c("backward", "forward", "seqrep"), pero puede ser recomendable emplear el paqueteMASSpara obtener directamente el modelo final.
6.3.2 Selección por pasos
Si el número de variables es grande (no sería práctico evaluar todas las posibilidades) se suele utilizar alguno (o varios) de los siguientes métodos:
Selección progresiva (forward): Se parte de una situación en la que no hay ninguna variable y en cada paso se incluye una aplicando un criterio de entrada (hasta que ninguna de las restantes lo verifican).
Eliminación progresiva (backward): Se parte del modelo con todas las variables y en cada paso se elimina una aplicando un criterio de salida (hasta que ninguna de las incluidas lo verifican).
Selección paso a paso (stepwise): Se combina un criterio de entrada y uno de salida. Normalmente se parte sin ninguna variable y en cada paso puede haber una inclusión y posteriormente la exclusión de alguna de las anteriormente añadidas (forward/backward). Otra posibilidad es partir del modelo con todas las variables y en cada paso puede haber una exclusión y posteriormente la inclusión de alguna de las anteriormente eliminadas (backward/forward).
Hay que tener en cuenta que se tratan de algoritmos “avariciosos” (también denominados “voraces”), ya que en cada paso tratan de elegir la mejor opción, pero puede que el resultado final no sea la solución global óptima (de hecho es bastante habitual que los modelos finales sean diferentes).
La función stepAIC() del paquete MASS permite seleccionar el modelo por pasos33, hacia delante o hacia atrás según criterio AIC (Akaike Information Criterion) o BIC (Bayesian Information Criterion).
La función stepwise() del paquete RcmdrMisc es una interfaz de stepAIC() que facilita su uso.
Los métodos disponibles son "backward/forward", "forward/backward", "backward" y "forward".
Normalmente obtendremos un modelo más simple combinando el método por pasos hacia delante con el criterio BIC:
library(MASS)
library(RcmdrMisc)
modelo.completo <- lm(fidelida ~ . , data = train)
modelo <- stepwise(modelo.completo, direction = "forward/backward", criterion = "BIC")##
## Direction: forward/backward
## Criterion: BIC
##
## Start: AIC=694.72
## fidelida ~ 1
##
## Df Sum of Sq RSS AIC
## + velocida 1 5435.2 6478.5 602.32
## + producto 1 5339.6 6574.2 604.67
## + quejas 1 4405.4 7508.4 625.93
## + calidadp 1 3664.7 8249.1 640.98
## + facturac 1 2962.6 8951.2 654.05
## + publi 1 866.5 11047.3 687.71
## + web 1 572.1 11341.6 691.92
## + imgfvent 1 516.4 11397.4 692.70
## + precio 1 433.4 11480.4 693.87
## <none> 11913.8 694.72
## + garantia 1 248.7 11665.1 696.42
## + nprod 1 234.1 11679.6 696.62
## + soporte 1 59.0 11854.7 699.00
## + flexprec 1 35.9 11877.9 699.31
##
## Step: AIC=602.32
## fidelida ~ velocida
##
## Df Sum of Sq RSS AIC
## + calidadp 1 3288.7 3189.9 494.04
## + flexprec 1 1395.7 5082.9 568.58
## + producto 1 1312.1 5166.5 571.19
## + precio 1 254.7 6223.8 600.98
## <none> 6478.5 602.32
## + web 1 54.4 6424.2 606.05
## + nprod 1 45.1 6433.4 606.28
## + quejas 1 13.5 6465.1 607.06
## + facturac 1 9.6 6468.9 607.16
## + publi 1 8.4 6470.1 607.19
## + soporte 1 7.9 6470.6 607.20
## + garantia 1 4.8 6473.7 607.28
## + imgfvent 1 2.4 6476.1 607.34
## - velocida 1 5435.2 11913.8 694.72
##
## Step: AIC=494.04
## fidelida ~ velocida + calidadp
##
## Df Sum of Sq RSS AIC
## + web 1 175.4 3014.5 490.06
## + imgfvent 1 125.6 3064.3 492.68
## <none> 3189.9 494.04
## + precio 1 95.3 3094.6 494.26
## + publi 1 48.1 3141.8 496.68
## + soporte 1 29.4 3160.5 497.63
## + facturac 1 15.3 3174.6 498.34
## + nprod 1 9.7 3180.2 498.63
## + garantia 1 6.2 3183.7 498.80
## + quejas 1 5.2 3184.7 498.85
## + flexprec 1 4.8 3185.0 498.87
## + producto 1 3.6 3186.3 498.93
## - calidadp 1 3288.7 6478.5 602.32
## - velocida 1 5059.2 8249.1 640.98
##
## Step: AIC=490.06
## fidelida ~ velocida + calidadp + web
##
## Df Sum of Sq RSS AIC
## <none> 3014.5 490.06
## + precio 1 53.8 2960.7 492.26
## + soporte 1 24.2 2990.3 493.85
## + facturac 1 21.9 2992.6 493.97
## - web 1 175.4 3189.9 494.04
## + quejas 1 14.7 2999.8 494.36
## + flexprec 1 10.6 3004.0 494.58
## + producto 1 10.3 3004.2 494.59
## + garantia 1 9.7 3004.8 494.62
## + nprod 1 5.3 3009.3 494.86
## + imgfvent 1 2.5 3012.1 495.01
## + publi 1 0.2 3014.3 495.13
## - calidadp 1 3409.7 6424.2 606.05
## - velocida 1 4370.9 7385.4 628.36En la salida de texto de esta función, "<none>" representa el modelo actual en cada paso y se ordenan las posibles acciones dependiendo del criterio elegido (aunque siempre muestra el valor de AIC).
El algoritmo se detiene cuando ninguna de ellas mejora el modelo actual.
Como resultado devuelve el modelo ajustado final:
summary(modelo)##
## Call:
## lm(formula = fidelida ~ velocida + calidadp + web, data = train)
##
## Residuals:
## Min 1Q Median 3Q Max
## -12.1533 -1.8588 0.1145 3.0086 7.7625
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -1.2205 3.0258 -0.403 0.68724
## velocida 7.3582 0.4893 15.040 < 2e-16 ***
## calidadp 3.2794 0.2469 13.283 < 2e-16 ***
## web 1.4005 0.4649 3.012 0.00302 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 4.396 on 156 degrees of freedom
## Multiple R-squared: 0.747, Adjusted R-squared: 0.7421
## F-statistic: 153.5 on 3 and 156 DF, p-value: < 2.2e-16Cuando el número de variables explicativas es muy grande (o si el tamaño de la muestra es pequeño en comparación) pueden aparecer problemas al emplear los métodos anteriores (incluso pueden no ser aplicables). Una alternativa son los métodos de regularización (ridge regression, LASSO; Sección 6.7) o los de reducción de la dimensión (regresión con componentes principales o mínimos cuadrados parciales; Sección 6.8).
Por otra parte en los modelos anteriores no se consideraron interacciones entre predictores (para detalles sobre como incluir interacciones en modelos lineales ver por ejemplo la Sección 8.6 de Fernández-Casal et al., 2019).
Por ejemplo podríamos considerar como modelo completo respuesta ~ .*., que incluiría los efectos principales y las interacciones de orden 2 de todos los predictores.
En la práctica se suele comenzar con modelos aditivos y posteriormente se estudian posibles interacciones siguiendo un proceso interactivo (aunque también, por ejemplo, se podría considerar un nuevo modelo completo a partir de las variables seleccionadas en el modelo aditivo, incluyendo todas las posibles interacciones de orden 2, y posteriormente aplicar alguno de los métodos de selección anteriores). Como ya vimos en capítulos anteriores, en AE interesan algoritmos que puedan detectar e incorporar automáticamente efectos de interacción (en el siguiente capítulo veremos extensiones en este sentido).
References
También está disponible la función
step()del paquete basestatscon menos opciones.↩︎