3.5 Deficiencias del bootstrap uniforme
Supongamos un contexto paramétrico en el que la distribución poblacional, \(F\), es la \(\mathcal{U}\left( 0,\theta \right)\). Nuestro interés será hacer inferencia acerca del parámetro \(\theta\), para lo cual, dada una muestra observada, \(\mathbf{X}=\left( X_1,X_2,\ldots ,X_n \right)\), consideraremos el estimador máximo verosímil en este contexto: \(\hat{\theta}=X_{(n)}\). Para realizar dicha inferencia estaremos interesados en aproximar la distribución de \(R\left( \mathbf{X},F \right) =\hat{\theta}-\theta\)
La función de distribución en el muestreo, \(G\left( x \right)\), de \(\hat{\theta}\) puede calcularse de forma sencilla:\[\begin{aligned} G\left( x \right) &= P\left( \hat{\theta}\leq x \right) =P\left( X_{\left( n \right)}\leq x \right) =P\left( X_i\leq x\,,\forall i\in \left\{ 1,\ldots n\right\} \right) \\ &= \prod_{i=1}^{n}P\left( X_i\leq x \right) =F\left( x \right)^{n}=\left( \frac{x}{\theta } \right)^{n},\text{ si }x\in \left[ 0,\theta \right]\end{aligned}\]
con lo cual su función de densidad viene dada por \[g\left( x \right) =\frac{n}{\theta }\left( \frac{x}{\theta } \right)^{n-1}, \text{ si }x\in \left[ 0,\theta \right] .\] Tomando, por ejemplo, \(\theta =1\) y \(n=50\), esta función de densidad resulta :
theta <- 1
n <- 50
curve(n/theta * (x/theta)^(n - 1), 0, theta, ylab = "Density")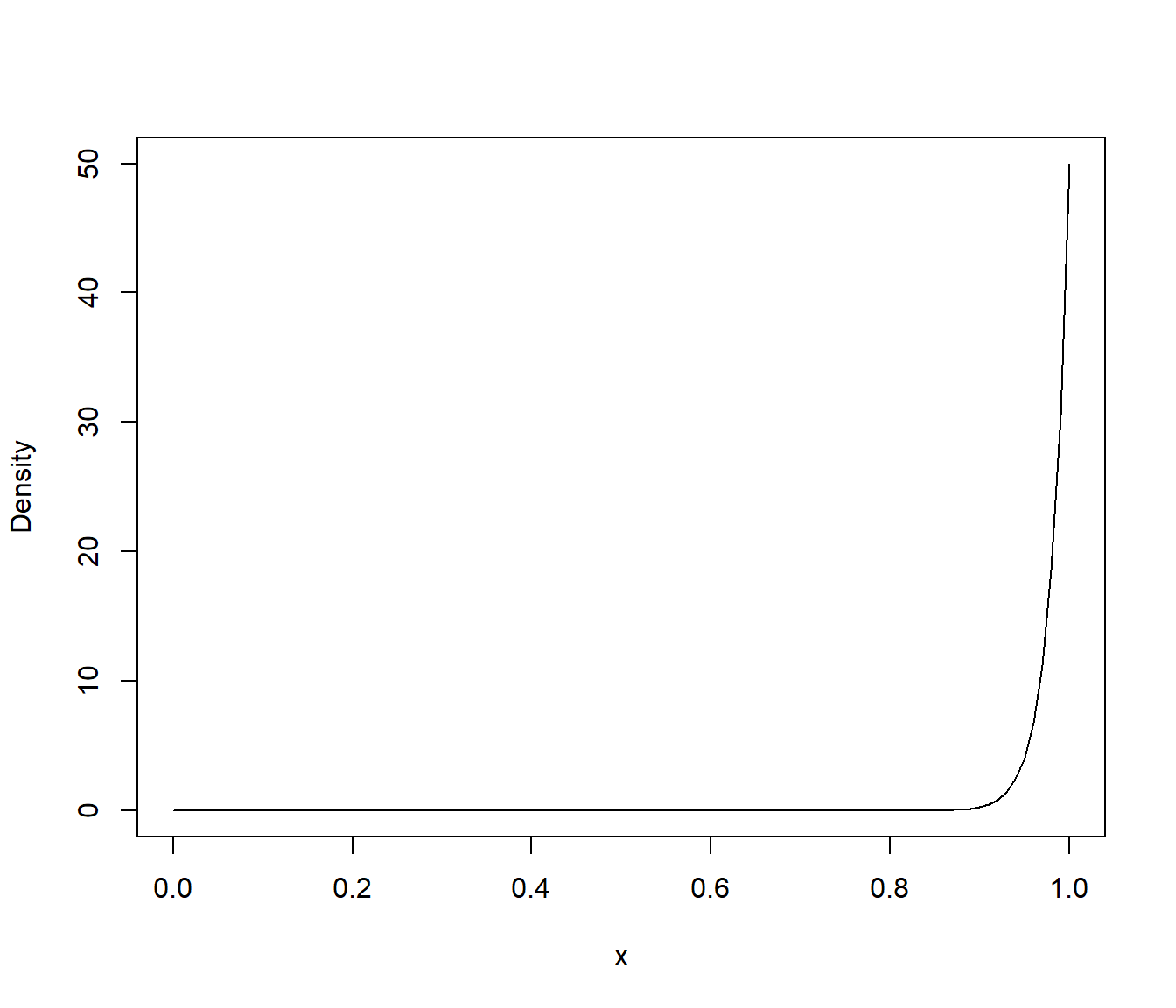
Figura 3.6: Función de densidad del máximo de una muestra procedente de una uniforme.
Como consecuencia podemos hallar fácilmente el sesgo del estimador \(\hat{\theta}\), ya que \[E\left( \hat{\theta} \right) =\int_{0}^{\theta }x\frac{n}{\theta }\left( \frac{x}{\theta } \right)^{n-1}dx=\left[ \frac{n}{n+1}\frac{x^{n+1}}{\theta ^{n}}\right] _{x=0}^{x=\theta }=\frac{n}{n+1}\theta ,\] con lo cual \[Sesgo\left( \hat{\theta} \right) =E\left( \hat{\theta} \right) -\theta = -\frac{\theta }{n+1}.\] Se ve claramente que \(\hat{\theta}\) es un estimador sesgado de \(\theta\), puesto que se tiene que \(\hat{\theta}\leq \theta\) con probabilidad 1.
Si deseamos aproximar mediante bootstrap la distribución en el muestreo de \(\hat{\theta}\) (o la de \(R\)) y utilizamos un bootstrap uniforme (naïve), la versión bootstrap del estimador resulta ser \(\hat{\theta}^{\ast }=X_{(n)}^{\ast}\), siendo \(\mathbf{X}^{\ast}=\left( X_1^{\ast}\text{, }X_2^{\ast}\text{, }\ldots \text{, }X_n^{\ast } \right)\) una remuestra bootstrap obtenida a partir de la distribución empírica \(F_n\). La distribución en el remuestreo de \(\hat{\theta} ^{\ast}\,\) resulta un poco más complicada pues es discreta y sólo puede tomar cualquiera de los valores de la muestra.
Suponiendo que no hay empates en las observaciones de la muestra, es fácil darse cuenta de que \[P^{\ast}\left( \hat{\theta}^{\ast}\leq X_{(j)} \right) =P^{\ast}\left( X_{(n)}^{\ast}\leq X_{(j) } \right) =P^{\ast}\left( X_i^{\ast}\leq X_{(j)}\,, 1 \leq i \leq n \right) =\left( \frac{j}{n} \right)^{n}\] y, por tanto, su masa de probabilidad viene dada por \[P^{\ast}\left( \hat{\theta}^{\ast}=X_{(j)} \right) =\left( \frac{j}{n} \right)^{n}-\left( \frac{j-1}{n} \right)^{n}\text{, }j=1,\ldots,n.\]
En particular, \[P^{\ast}\left( \hat{\theta}^{\ast}=X_{(n)} \right) =1-\left( 1- \frac{1}{n} \right)^{n}\rightarrow 1-\frac{1}{e}\simeq 0.6321,\] con lo cual la distribución en remuestreo de \(R^{\ast}=R\left( \mathbf{X}^{\ast},F_n \right) =\hat{\theta}^{\ast}-X_{\left( n \right)}\) tiene un átomo de probabilidad en el valor \(0\) cuya probabilidad tiende a \(1-\frac{1}{e}\) cuando el tamaño muestral tiende a infinito, es decir
\[\lim_{n\rightarrow \infty }P^{\ast}\left( R^{\ast}=0 \right) =1-\frac{1}{e},\]
cosa que no ocurre con la distribución en el muestreo de \(R\), que es continua con densidad: \[g_R\left( x \right) =\frac{n}{\theta }\left( \frac{x + \theta}{\theta } \right)^{n-1}, \text{ si }x\in \left[ -\theta, 0\right].\] De esta forma vemos que el bootstrap uniforme (no paramétrico) es inconsistente.
Ejemplo 3.3 (Inferencia sobre el máximo de una distribución uniforme) El siguiente código implementa el método bootstrap uniforme (también llamado naïve) para aproximar la distribución del estadístico \(R=\hat{\theta}-\theta\), para una muestra de tamaño \(n=50\), proveniente de una población con distribución \(\mathcal{U}\left( 0,1\right)\) :
theta <- 1
n <- 50
set.seed(1)
muestra <- runif(50) * theta
theta_est <- max(muestra)
# Remuestreo
B <- 2000
maximo <- numeric(B)
estadistico <- numeric(B)
for (k in 1:B) {
remuestra <- sample(muestra, n, replace = TRUE)
maximo[k] <- max(remuestra)
estadistico[k] <- maximo[k] - theta_est
}
# Distribución estadístico
xlim <- c(-theta/2, 0) # c(-theta, 0)
hist(estadistico, freq = FALSE, main = "", lty = 2,
border = "darkgray", xlim = xlim)
lines(density(estadistico))
rug(estadistico, col = "darkgray")
curve(n/theta * ((x + theta)/theta)^(n - 1), col = "blue", lty = 2, lwd = 2, add = TRUE)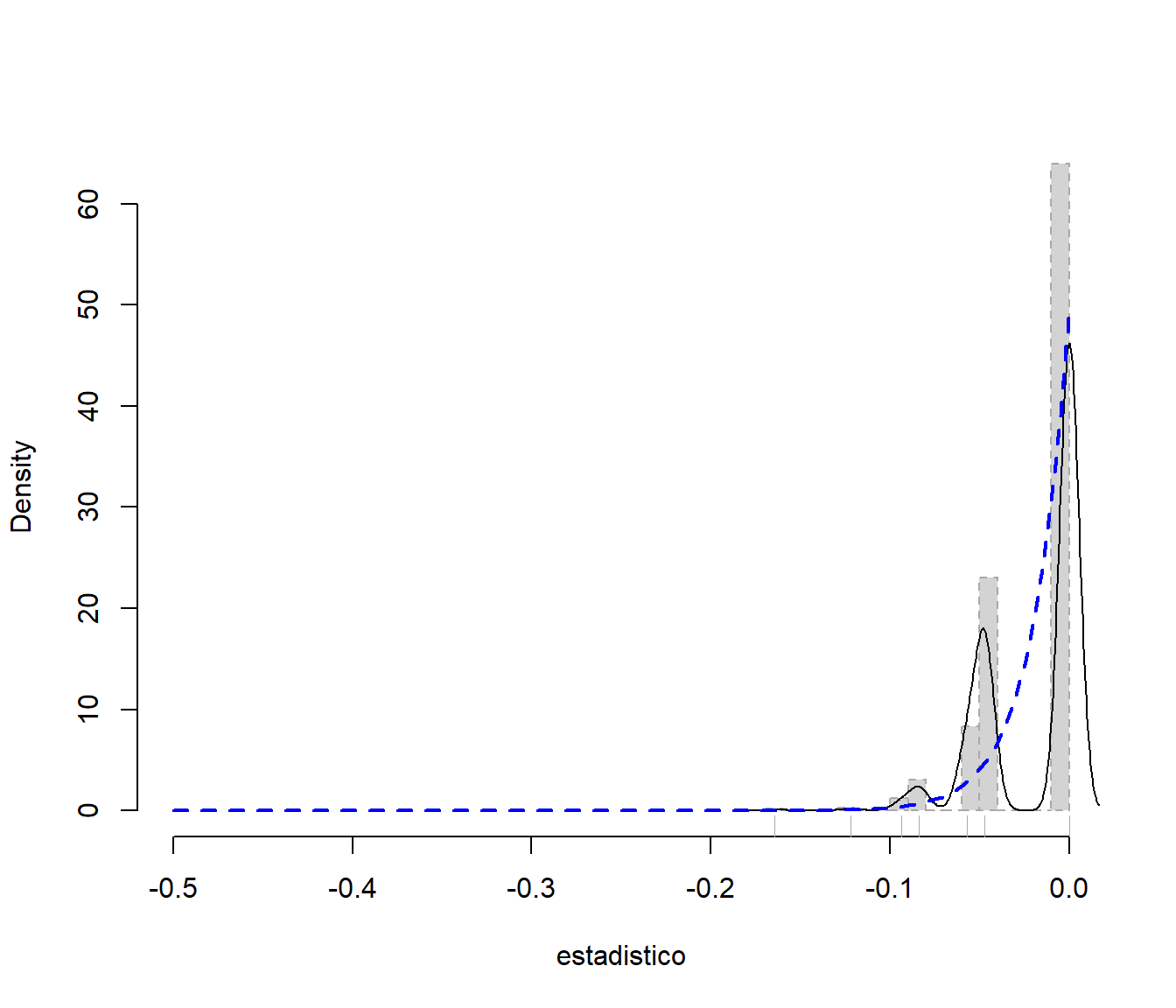
Figura 3.7: Distribución de las réplicas bootstrap (uniforme) del estadístico y distribución poblacional.
3.5.1 Ejemplo (método alternativo)
En este contexto, al conocer la familia paramétrica (\(\mathcal{U}\left( 0,\theta \right)\)) a la cual pertenece la distribución de la población de partida, lo natural sería utilizar un bootstrap paramétrico, consistente en obtener las remuestras bootstrap a partir de una distribución uniforme con parámetro estimado: \[\mathbf{X}^{\ast}=\left( X_1^{\ast}\text{, }X_2^{\ast}\text{, }\ldots \text{, }X_n^{\ast} \right), \text{ con } X_i^{\ast} \sim \mathcal{U}\left( 0,\hat{\theta}\right).\] En estas circunstancias es muy sencillo obtener la distribución en el remuestreo de \(\hat{\theta}^{\ast}\), ya que su deducción es totalmente paralela a la de la distribución en el muestreo de \(\hat{\theta}\). Así, la función de densidad de \(\hat{\theta}^{\ast}\) es \[\hat{g}\left( x \right) =\frac{n}{\hat{\theta}}\left( \frac{x}{\hat{\theta}} \right)^{n-1},\text{ si }x\in \left[ 0,\hat{\theta}\right] .\]
Con lo cual, al utilizar un bootstrap paramétrico, la distribución en el remuestreo de \(R^{\ast}=R\left( \mathbf{X}^{\ast},F_{\hat{ \theta}} \right) =\hat{\theta}^{\ast}-\hat{\theta}\) imita a la distribución en muestreo de \(R=R\left( \mathbf{X},F \right) =\hat{\theta}-\theta\).
Ejemplo 3.4 (Inferencia sobre el máximo de una distribución uniforme, continuación) Para emplear el bootstrap paramétrico (que remuestrea de una distribución uniforme con parámetro estimado) podríamos emplear un código muy similar al del Ejemplo 3.3 :
# Remuestreo
B <- 2000
maximo <- numeric(B)
estadistico <- numeric(B)
for (k in 1:B) {
remuestra <- runif(n) * theta_est
maximo[k] <- max(remuestra)
estadistico[k] <- maximo[k] - theta_est
}
# Distribución estadístico
xlim <- c(-theta/2, 0) # c(-theta, 0)
hist(estadistico, freq = FALSE, main = "", lty = 2,
border = "darkgray", xlim = xlim)
lines(density(estadistico))
rug(estadistico, col = "darkgray")
curve(n/theta * ((x + theta)/theta)^(n - 1), col = "blue", lty = 2, lwd = 2, add = TRUE)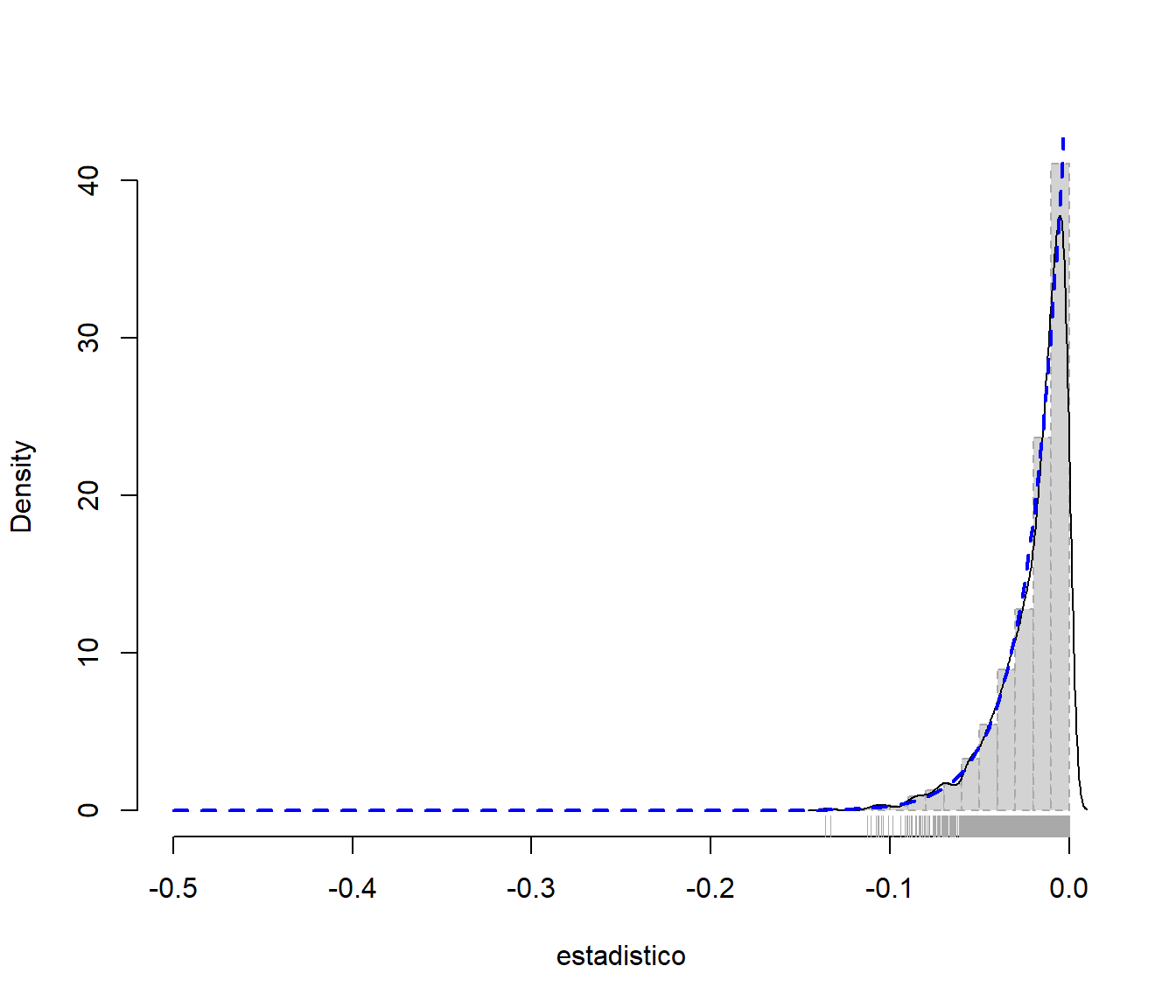
Figura 3.8: Distribución bootstrap paramétrica y distribución poblacional.