9.3 Bootstrap suavizado
Cuando la distribución poblacional, \(F\), es continua es lógico incorporar dicha información al bootstrap. Eso significa que la función de distribución tiene una función de densidad asociada, relacionadas mediante la expresión: \(f(x) =F^{\prime}(x)\). Una forma de remuestrear de un universo bootstrap continuo es emplear un estimador de la función de densidad, como por ejemplo el estimador no paramétrico tipo núcleo, y remuestrear de él.
Si \(\left( X_1, X_2, \ldots, X_n \right)\) es una muestra aleatoria simple (m.a.s.), de una población con función de distribución \(F\), absolutamente continua, y función de densidad \(f\), el estimador tipo núcleo propuesto por Parzen (1962) y Rosenblatt (1956) viene dado por \[\hat{f}_{h}\left( x \right) =\frac{1}{nh}\sum_{i=1}^{n}K\left( \frac{x-X_i}{h} \right) =\frac{1}{n}\sum_{i=1}^{n}K_{h}\left( x-X_i \right),\] donde \(K_{h}\left( u \right) =\frac{1}{h}K\left( \frac{u}{h} \right)\), \(K\) es una función núcleo (normalmente una densidad simétrica en torno al cero) y \(h>0\) es una parámetro de suavizado, llamado ventana, que regula el tamaño del entorno que se usa para llevar a cabo la estimación.
Es habitual seleccionar una función núcleo \(K\) no negativa y con integral uno: \[K\left( u \right) \geq 0,~\forall u,~\int_{-\infty }^{\infty } K\left( u \right) du=1\] (i.e. una función de densidad). Además, frecuentemente \(K\) es una función simétrica (\(K\left( -u \right) =K\left( u \right)\)). Aunque la elección de esta función no tiene gran impacto en las propiedades del estimador (salvo sus condiciones de regularidad: continuidad, diferenciabilidad, etc.) la elección del parámetro de suavizado sí es muy importante para una correcta estimación. En otras palabras, el tamaño del entorno usado para la estimación no paramétrica debe ser adecuado (ni demasiado grande ni demasiado pequeño).
En R podemos emplear la función density() del paquete base para obtener
una estimación tipo núcleo de la densidad.
Los principales parámetros (con los valores por defecto) son los siguientes:
density(x, bw = "nrd0", adjust = 1, kernel = "gaussian", n = 512, from, to)bw: ventana, puede ser un valor numérico o una cadena de texto que la determine (en ese caso llamará internamente a la funciónbw.xxx()dondexxxse corresponde con la cadena de texto). Las opciones son:"nrd0","nrd": Reglas del pulgar de Silverman (1986, page 48, eqn (3.31)) y Scott (1992), respectivamente. Como es de esperar que la densidad objetivo no sea tan suave como la normal, estos criterios tenderán a seleccionar ventanas que producen un sobresuavizado de las observaciones."ucv","bcv": Métodos de validación cruzada insesgada y sesgada, respectivamente."sj","sj-ste","sj-dpi": Métodos de Sheather y Jones (1991), “solve-the-equation” y “direct plug-in,” respectivamente.
adjust: parameto para reescalado de la ventana, las estimaciones se calculan con la ventanaadjust*bw.kernel: cadena de texto que determina la función núcleo, las opciones son:"gaussian","epanechnikov","rectangular","triangular","biweight","cosine"y"optcosine".n,from,to: permiten establecer la rejilla en la que se obtendrán las estimaciones (si \(n>512\) se empleafft()por lo que se recomienda establecerna un múltiplo de 2; por defectofromytose establecen comocut = 3veces la ventana desde los extremos de las observaciones).
Como ejemplo consideraremos el conjunto de datos precip, que contiene el promedio de precipitación,
en pulgadas de lluvia, de 70 ciudades de Estados Unidos.
x <- precip
h <- bw.SJ(x)
npden <- density(x, bw = h)
# npden <- density(x, bw = "SJ")
# h <- npden$bw
# plot(npden)
hist(x, freq = FALSE, breaks = "FD", main = "Kernel density estimation",
xlab = paste("Bandwidth =", formatC(h)), border = "darkgray",
xlim = c(0, 80), ylim = c(0, 0.04))
lines(npden, lwd = 2)
rug(x, col = "darkgray")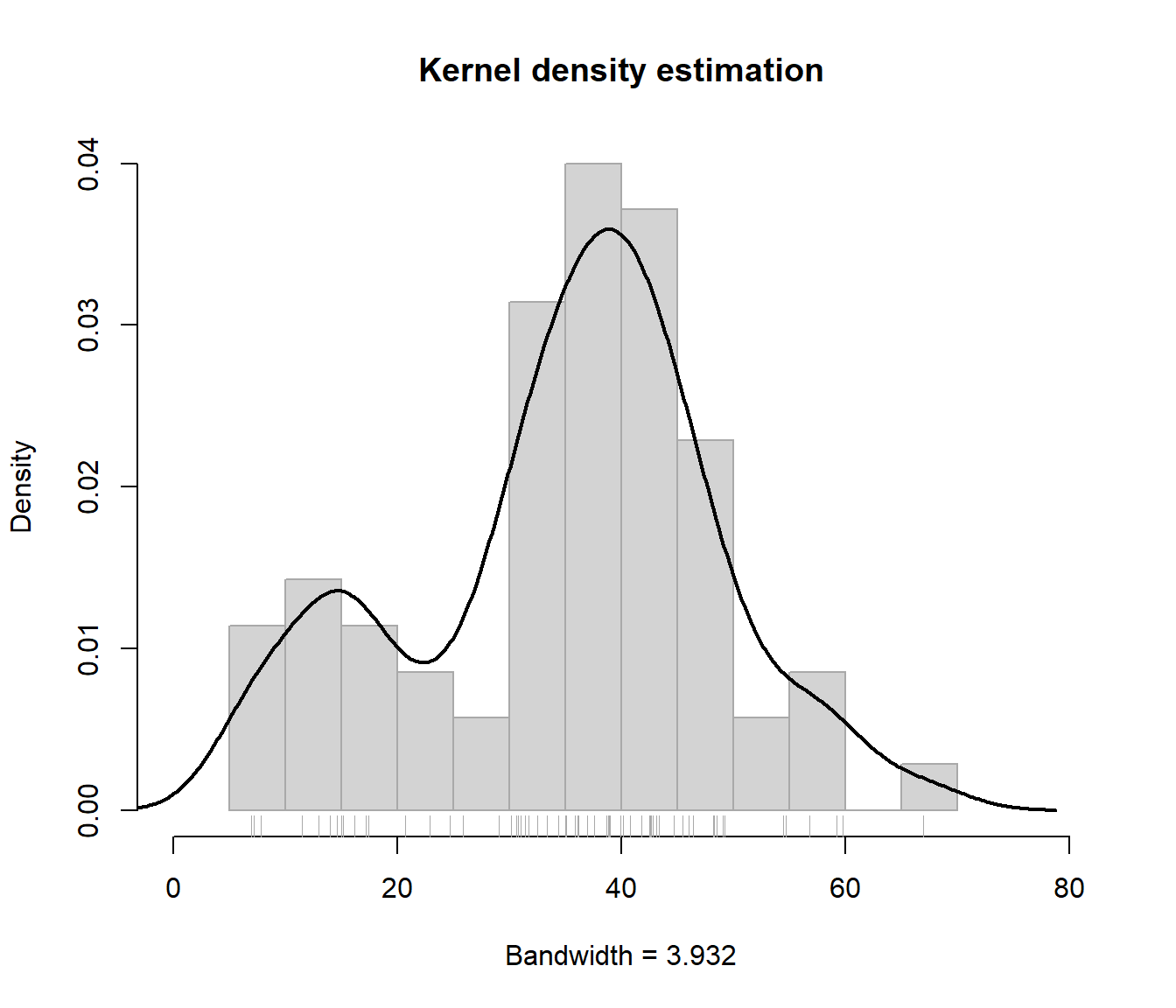
Figura 9.4: Estimación tipo núcleo de la densidad de precip.
Alternativamente podríamos emplear implementaciones en otros paquetes de R.
Uno de los más empleados es ks (Duong, 2019), que admite estimación incondicional y condicional multidimensional.
También se podrían emplear los paquetes KernSmooth (Wand y Ripley, 2019), sm (Bowman y Azzalini, 2019), np (Tristen y Jeffrey, 2019), kedd (Guidoum, 2019), features (Duong y Matt, 2019) y npsp (Fernández-Casal, 2019), entre otros.
La función de distribución asociada al estimador tipo núcleo de la función de densidad viene dada por \[\begin{aligned} \hat{F}_{h}\left( x \right) &= \int_{-\infty }^{x}\hat{f}_{h}\left( y \right) dy =\int_{-\infty }^{x}\frac{1}{n}\sum_{i=1}^{n}\frac{1}{h} K\left( \frac{y-X_i}{h} \right) dy \\ &= \frac{1}{nh}\sum_{i=1}^{n}\int_{-\infty }^{x} K\left( \frac{y-X_i}{h} \right) dy \\ &= \frac{1}{n}\sum_{i=1}^{n}\int_{-\infty }^{\frac{x-X_i}{h}}K\left( u \right) du =\frac{1}{n}\sum_{i=1}^{n}\mathbb{K}\left( \frac{x-X_i}{h} \right) \end{aligned}\] donde \(\mathbb{K}\) es la función de distribución asociada al núcleo \(K\), es decir \[\mathbb{K}\left( t \right) =\int_{-\infty }^{t}K\left(u \right) du.\]
Por ejemplo, en el caso de del conjunto de datos de precipitaciones, el siguiente código compara la estimación tipo núcleo de la distribución con la empírica:
Fn <- ecdf(precip)
curve(Fn, xlim = c(0, 75), ylab = "F(x)", type = "s")
Fnp <- function(x) sapply(x, function(y) mean(pnorm(y, precip, h)))
curve(Fnp, lty = 2, add = TRUE)
legend("bottomright", legend = c("Empírica", "Tipo núcleo"), lty = 1:2)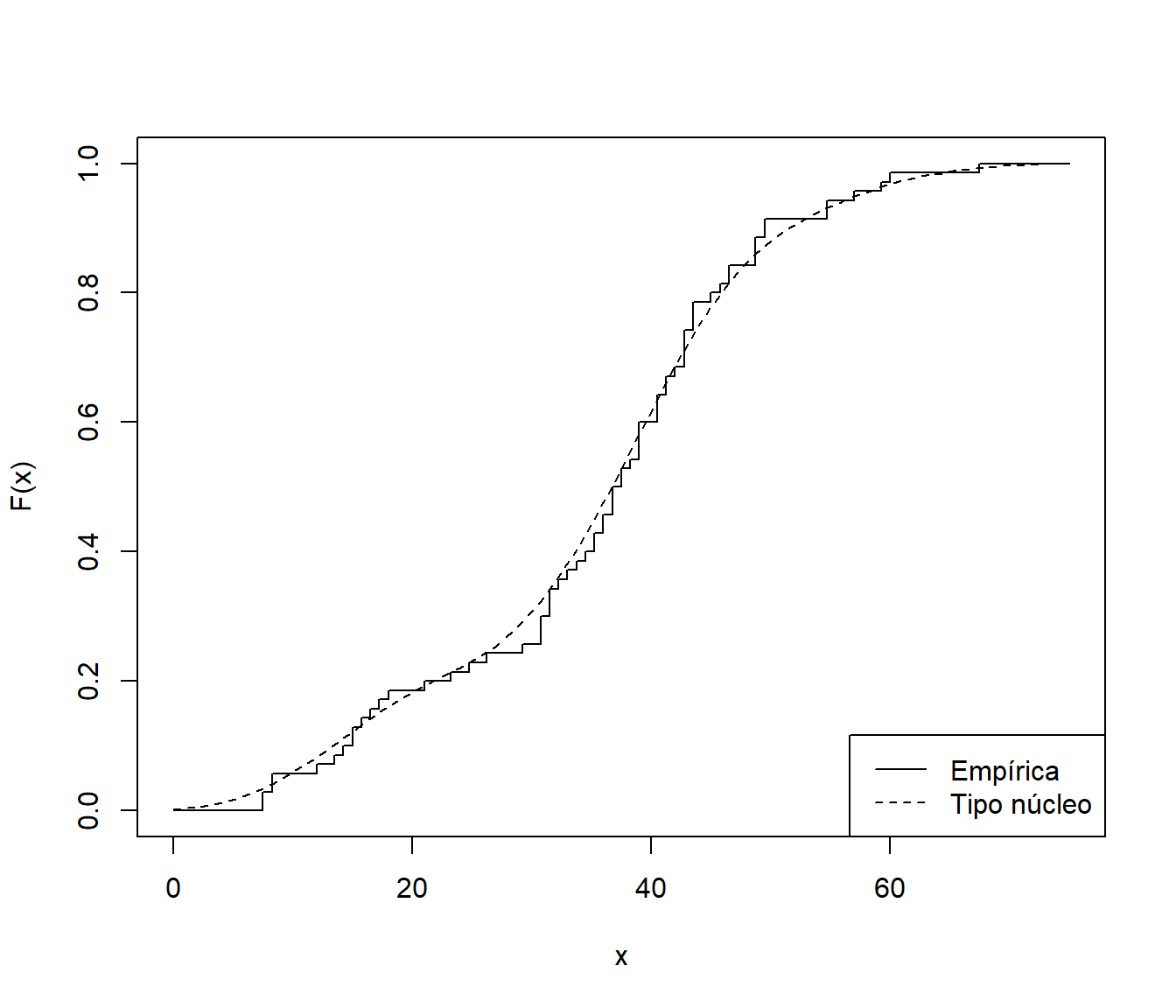
Figura 9.5: Estimación empírica y tipo núcleo de la función de distribución de precip.
Tendiendo en cuenta que el estimador \(\hat{f}_{h}\left( x \right)\) es una combinación lineal convexa de funciones de densidad, \(K_{h}\left(x-X_i \right)\), con pesos \(\frac{1}{n}\), podemos simular valores \(X^{\ast}\), procedentes de esta distribución empleando el método de composición descrito en la Sección 4.4. El primer paso consistiría en elegir (aleatoriamente y con equiprobabilidad) un índice \(i\in \left\{ 1,\ldots ,n\right\}\), y posteriormente simular \(X^{\ast}\) a partir de la densidad \(K_{h}\left(\cdot -X_i \right)\). Este último paso puede realizarse simulando un valor \(V\) con densidad \(K\) y haciendo \(X_i+hV\). Por tanto, podemos pensar que el bootstrap suavizado parte del bootstrap uniforme (\(X_i^{\ast}=X_{\left\lfloor nU_i\right\rfloor +1}\)) y añade una perturbación (\(hV_i\)), cuya magnitud viene dada por el parámetro de suavizado (\(h\)) y cuya forma imita a la de una variable aleatoria (\(V_i\)) con densidad \(K\).
Por ejemplo, la función density() emplea por defecto un núcleo gaussiano, y como se muestra en la ayuda de esta función, podemos emplear un código como el siguiente para obtener nsim simulaciones(ver Figura 9.6):
## simulation from a density() fit:
# a kernel density fit is an equally-weighted mixture.
nsim <- 1e6
set.seed(1)
# x_boot <- sample(x, nsim, replace = TRUE)
# x_boot <- x_boot + bandwidth * rnorm(nsim)
x_boot <- rnorm(nsim, sample(x, nsim, replace = TRUE), h)
# Representar
plot(npden, main = "")
lines(density(x_boot), col = "blue", lwd = 2, lty = 2)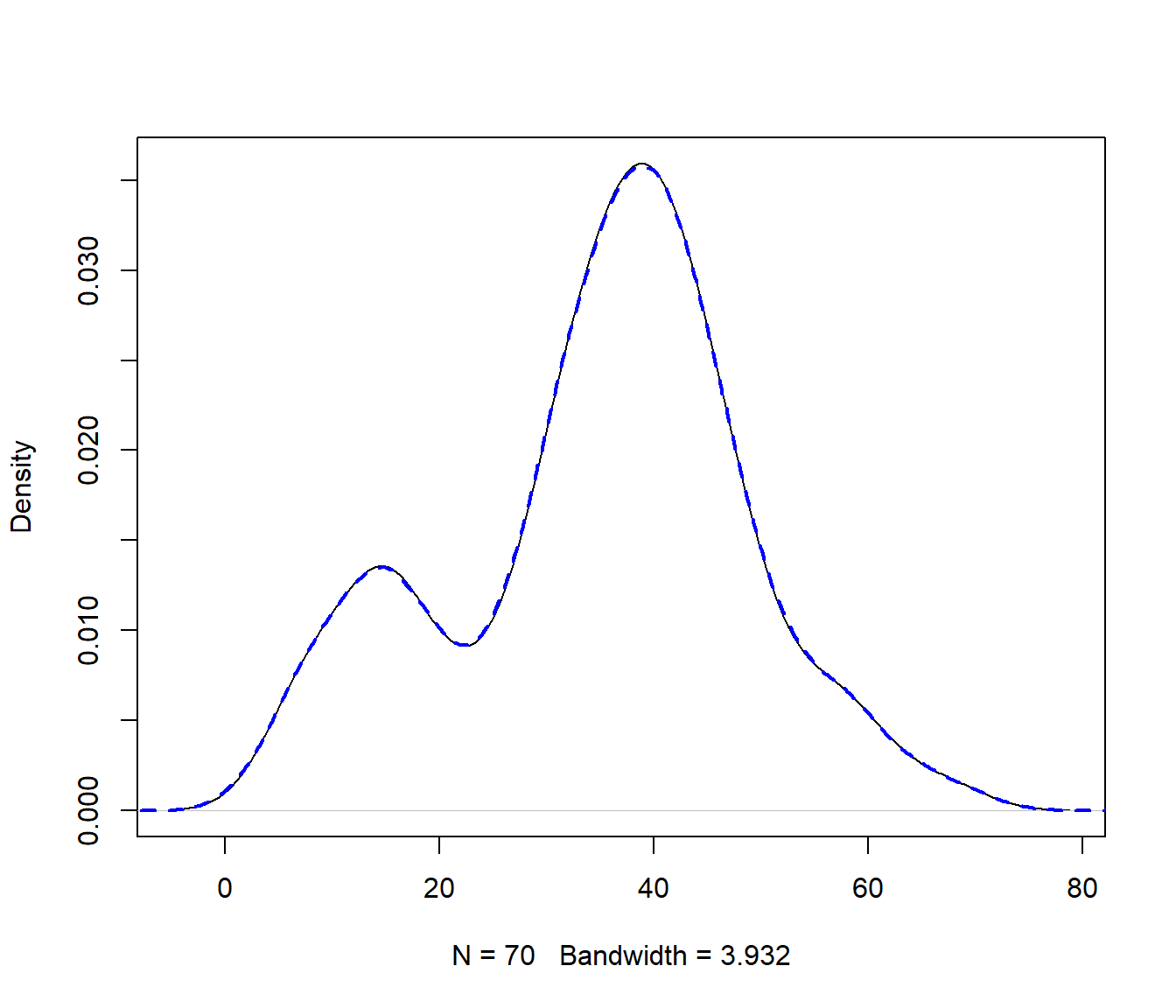
Figura 9.6: Estimaciónes tipo núcleo de las densidades de precip y de una simulación.
En el boostrap suavizado, la distribución de una observación \(X_i^{\ast}\) de la remuestra bootstrap es continua (puede tomar infinitos valores), mientras que en el bootstrap uniforme es discreta. De esta forma se pueden evitar algunos de los problemas del bootstrap uniforme, como los descritos en la Sección 9.1. Un problema importante es la elección del parámetro de suavizado, \(h\), en este procedimiento de remuestreo. En la práctica es razonable elegir \(h\) como un valor bastante pequeño, en relación con la desviación típica de la muestra. Es fácil observar que en el caso extremo \(h=0\) este método de remuestreo se reduce al bootstrap uniforme.
Ejemplo 9.4 (Inferencia sobre la media, continuación)
Continuando con el Ejemplo 8.2 del tiempo de vida de microorganismos, podríamos pensar en emplear bootstrap suavizado para calcular un intervalo de confianza para la media poblacional.
muestra <- simres::lifetimes
n <- length(muestra)
alfa <- 0.05
# Estimaciones muestrales
x_barra <- mean(muestra)
cuasi_dt <- sd(muestra)
# Remuestreo
set.seed(1)
B <- 1000
# h <- 1e-08
# h <- 0.05*cuasi_dt
h <- bw.SJ(muestra)/2
estadistico_boot <- numeric(B)
for (k in 1:B) {
# remuestra <- sample(muestra, n, replace = TRUE)
# remuestra <- rexp(n, 1/x_barra)
remuestra <- rnorm(n, sample(muestra, n, replace = TRUE), h)
x_barra_boot <- mean(remuestra)
cuasi_dt_boot <- sd(remuestra)
estadistico_boot[k] <- sqrt(n) * (x_barra_boot - x_barra)/cuasi_dt_boot
}
# Aproximación Monte Carlo de los ptos críticos:
pto_crit <- quantile(estadistico_boot, c(alfa/2, 1 - alfa/2))
# Construcción del IC
ic_inf_boot <- x_barra - pto_crit[2] * cuasi_dt/sqrt(n)
ic_sup_boot <- x_barra - pto_crit[1] * cuasi_dt/sqrt(n)
IC_boot <- c(ic_inf_boot, ic_sup_boot)
names(IC_boot) <- paste0(100*c(alfa/2, 1-alfa/2), "%")
IC_boot## 2.5% 97.5%
## 0.4960975 1.1880279Con el paquete boot, la recomendación es implementarlo como
un bootstrap paramétrico:
library(boot)
ran.gen.smooth <- function(data, mle) {
# Función para generar muestras aleatorias mediante
# bootstrap suavizado con función núcleo gaussiana,
# mle contendrá la ventana.
n <- length(data)
h <- mle
out <- rnorm(n, sample(data, n, replace = TRUE), h)
out
}
statistic <- function(data){
c(mean(data), var(data)/length(data))
}
set.seed(1)
res.boot <- boot(muestra, statistic, R = B, sim = "parametric",
ran.gen = ran.gen.smooth, mle = h)
boot.ci(res.boot, type = "stud")## BOOTSTRAP CONFIDENCE INTERVAL CALCULATIONS
## Based on 1000 bootstrap replicates
##
## CALL :
## boot.ci(boot.out = res.boot, type = "stud")
##
## Intervals :
## Level Studentized
## 95% ( 0.4960, 1.1927 )
## Calculations and Intervals on Original ScaleEn el Capítulo 6 de Cao y Fernández-Casal (2022) se describen métodos bootstrap diseñados específicamente para hacer inferencia sobre la densidad empleando el estimador no paramétrico tipo núcleo (i.e. empleando bootstrap suavizado), como la construcción de intervalos de confianza o la selección del parámetro de suavizado.