Capítulo 8 Redes neuronales
Las redes neuronales (McCulloch y Pitts, 1943), también conocidas como redes de neuronas artificiales (artificial neural network; ANN), son una metodología de aprendizaje supervisado que destaca porque da lugar a modelos con un número muy elevado de parámetros, adecuada para abordar problemas con estructuras subyacentes muy complejas, pero de muy difícil interpretación. Con la aparición de las máquinas de soporte vectorial y del boosting, las redes neuronales perdieron popularidad, pero en los últimos años la han recuperado, sobre todo gracias al incremento de las capacidades de computación. El diseño y el entrenamiento de una red neuronal suele requerir de más tiempo y experimentación, y también de más experiencia, que otros algoritmos de aprendizaje estadístico. Además, el gran número de hiperparámetros lo convierte en un problema de optimización complicado. En este capítulo se va a hacer una breve introducción a esta metodología; para poder emplearla con solvencia en la práctica, sería muy recomendable profundizar más en ella (por ejemplo, en Chollet y Allaire, 2018, se puede encontrar un tratamiento detallado).
En los métodos de aprendizaje supervisado se realizan una o varias transformaciones del espacio de las variables predictoras buscando una representación óptima de los datos, para así poder conseguir una buena predicción. Los modelos que realizan una o dos transformaciones reciben el nombre de modelos superficiales (shallow models). Por el contrario, cuando se realizan muchas transformaciones se habla de aprendizaje profundo (deep learning). No nos debemos dejar engañar por la publicidad: que un aprendizaje sea profundo no significa que sea mejor que el superficial. Aunque es verdad que ahora mismo la metodología que está de moda son las redes neuronales profundas (deep neural networks), hay que ser muy consciente de que dependiendo del contexto será más conveniente un tipo de modelos u otro. Esta metodología resulta adecuada para problemas muy complejos, pero no tanto para problemas con pocas observaciones o pocos predictores. Hay que tener en cuenta que no existe ninguna metodología que sea “transversalmente” la mejor (lo que se conoce como el teorema no free lunch, Wolpert y Macready, 1997).
Una red neuronal básica, como la representada en la Figura 8.1, va a realizar dos transformaciones de los datos, y por tanto es un modelo con tres capas: una capa de entrada (input layer) consistente en las variables originales \(\mathbf{X} = (X_1,X_2,\ldots, X_p)\), otra capa oculta (hidden layer) con \(M\) nodos, y la capa de salida (output layer) con la predicción (o predicciones) final \(m(\mathbf{X})\).
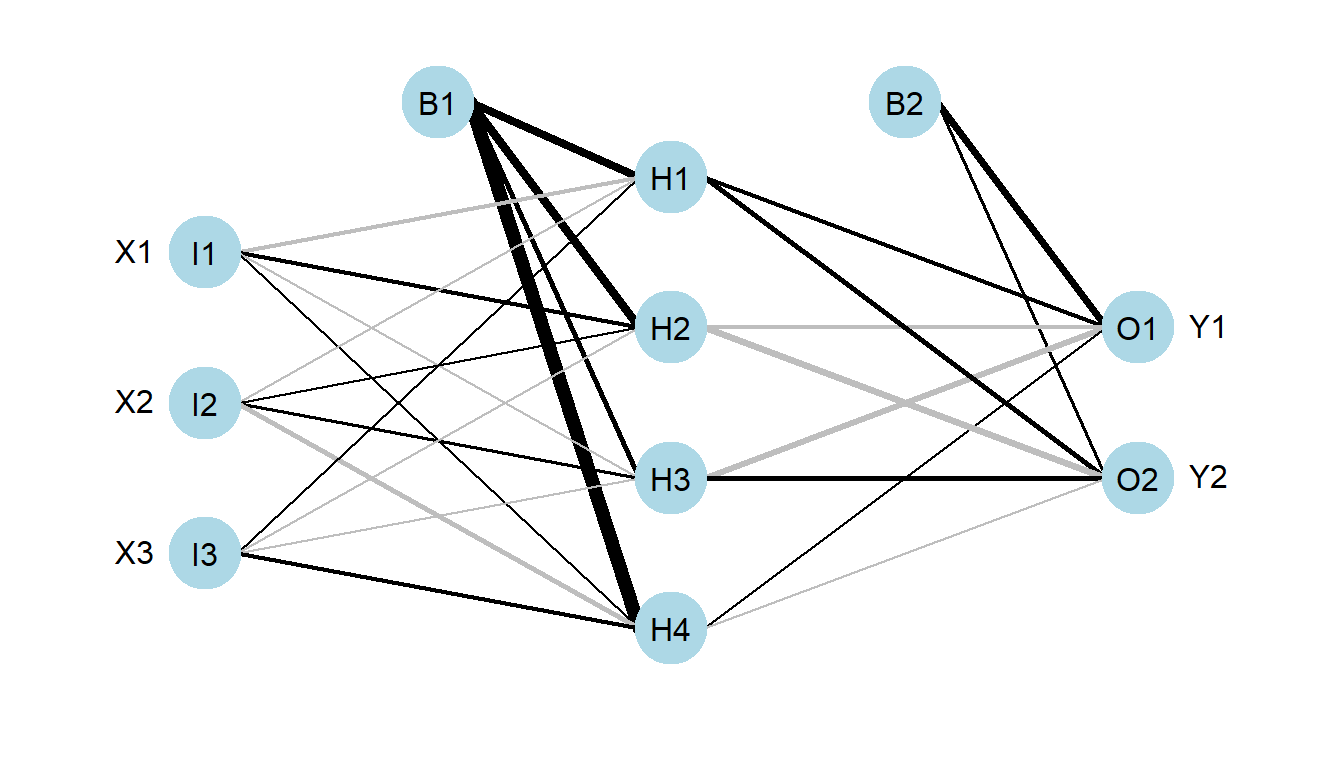
Figura 8.1: Diagrama de una red neuronal.
Para que las redes neuronales tengan un rendimiento aceptable se requiere disponer de tamaños muestrales grandes, debido a que son modelos hiperparametrizados (y por tanto de difícil interpretación). El ajuste de estos modelos puede requerir mucho tiempo de computación, incluso si están implementados de forma muy eficiente (por ejemplo, empleando computación en paralelo con GPUs), y solo desde fechas recientes es viable utilizarlos con un número elevado de capas (deep neural networks). Además, las redes neuronales son muy sensibles a la escala de los predictores, por lo que requieren de un preprocesado para su homogeneización; y pueden presentar problemas de colinealidad.
Una de las fortalezas de las redes neuronales es que sus modelos son muy robustos frente a predictores irrelevantes. Esto la convierte en una metodología muy interesante cuando se dispone de datos de dimensión muy alta. Otros métodos requieren un preprocesado muy costoso, pero las redes neuronales lo realizan de forma automática en las capas intermedias, que de forma sucesiva se van centrado en los aspectos relevantes de los datos. Y una de sus debilidades es que conforme aumentan las capas se hace más difícil la interpretación del modelo, hasta convertirse en una auténtica caja negra.
Hay distintas formas de construir redes neuronales. La básica recibe el nombre de feedforward (o también multilayer perceptron). Otras formas, con sus campos de aplicación principales, son:
Convolutional neural networks para reconocimiento de imagen y vídeo.
Recurrent neural networks para reconocimiento de voz.
Long short-term memory neural networks para traducción automática.